

Text-to-image diffusion models offer powerful image editing capabilities. To edit real images, many methods rely on the inversion of the image into Gaussian noise. A common approach to invert an image is to gradually add noise to the image, where the noise is determined by reversing the sampling equation. This process has an inherent tradeoff between reconstruction and editability, limiting the editing of challenging images such as highly-detailed ones. Recognizing the reliance of text-to-image models inversion on a text condition, this work explores the importance of the condition choice. We show that a condition that precisely aligns with the input image significantly improves the inversion quality. Based on our findings, we introduce Tight Inversion, an inversion method that utilizes the most possible precise condition – the input image itself. This tight condition narrows the distribution of the model’s output and enhances both reconstruction and editability. We demonstrate the effectiveness of our approach when combined with existing inversion methods through extensive experiments, evaluating the reconstruction accuracy as well as the integration with various editing methods.









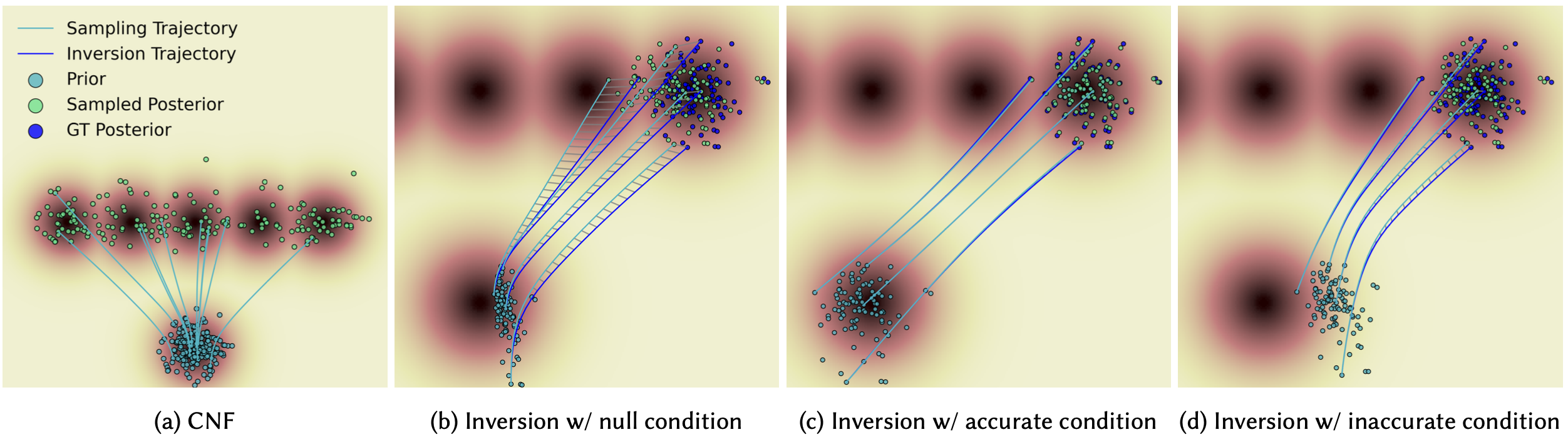
In Tight Inversion, we condition the image generation model on the image itself during both inversion and reconstruction. As demonstrated in the figure, this leads to the reconstruction trajectory being more aligned with the inversion trajectory. Additionally, with Tight Inversion, we reach latents that are more aligned with the prior distribution. Together, these properties lead to improved editability while maintaining faithfulness to the original input image.
@misc{kadosh2025tightinversionimageconditionedinversion,
title={Tight Inversion: Image-Conditioned Inversion for Real Image Editing},
author={Edo Kadosh and Nir Goren and Or Patashnik and Daniel Garibi and Daniel Cohen-Or},
year={2025},
eprint={2502.20376},
archivePrefix={arXiv},
primaryClass={cs.GR},
url={https://arxiv.org/abs/2502.20376},
}